We’ve developed a padding method called Adaptive Padding Early (APE) as part of basket2. APE is designed to be an early implementation of an adaptive padding based defense against website fingerprinting attacks, related to the WTF-PAD defense by Juarez et al.. APE tries to make simple, but probably naive, changes to the complex WTF-PAD design to be an improvement (in terms of overhead) over Tamaraw while still offering significantly better protection than the Obfs4 censorship resistance methods against WF attacks. Once WTF-PAD has a practical approach to, e.g. histogram generation, APE should be abandoned. We plan to have the final version of APE in spring.
APE shows that it’s a primitive version of WTF-PAD primarily in the following way: since optimal distributions/histograms is the problem with deploying WTF-PAD, we in search for a “good enough” solution in APE create randomised (biased) distributions like Obfs4 and ScrambleSuit per connection. In the case of APE, we create randomized log-normal distributions and increase the overhead over what WTF-PAD reports in the hope of being annoying enough for an attacker.
Let’s look closer at the good, the bad, and the ugly of APE.
The good
It seems like APE is a decent defense against Wa-kNN. If you want to see how well Obfs4 stands up against Wa-kNN, see our prior evaluations of basket2 methods [1,2,3]. For now, we’re going to focus on the padding methods APE, Null, and Tamaraw (as implemented in basket2). Further, we’re going to put our pluggable transports server (bridge) in three locations: on the same local network as the clients in Sweden (se), in Germany (de), and in Canada (ca). We use the same infrastructure as in our third basket2 evaluation.
Here are the results for recall and precision on 100x100+10k datasets collected with our gathering tools on real network traffic and a proof-of-concept implementation of APE:
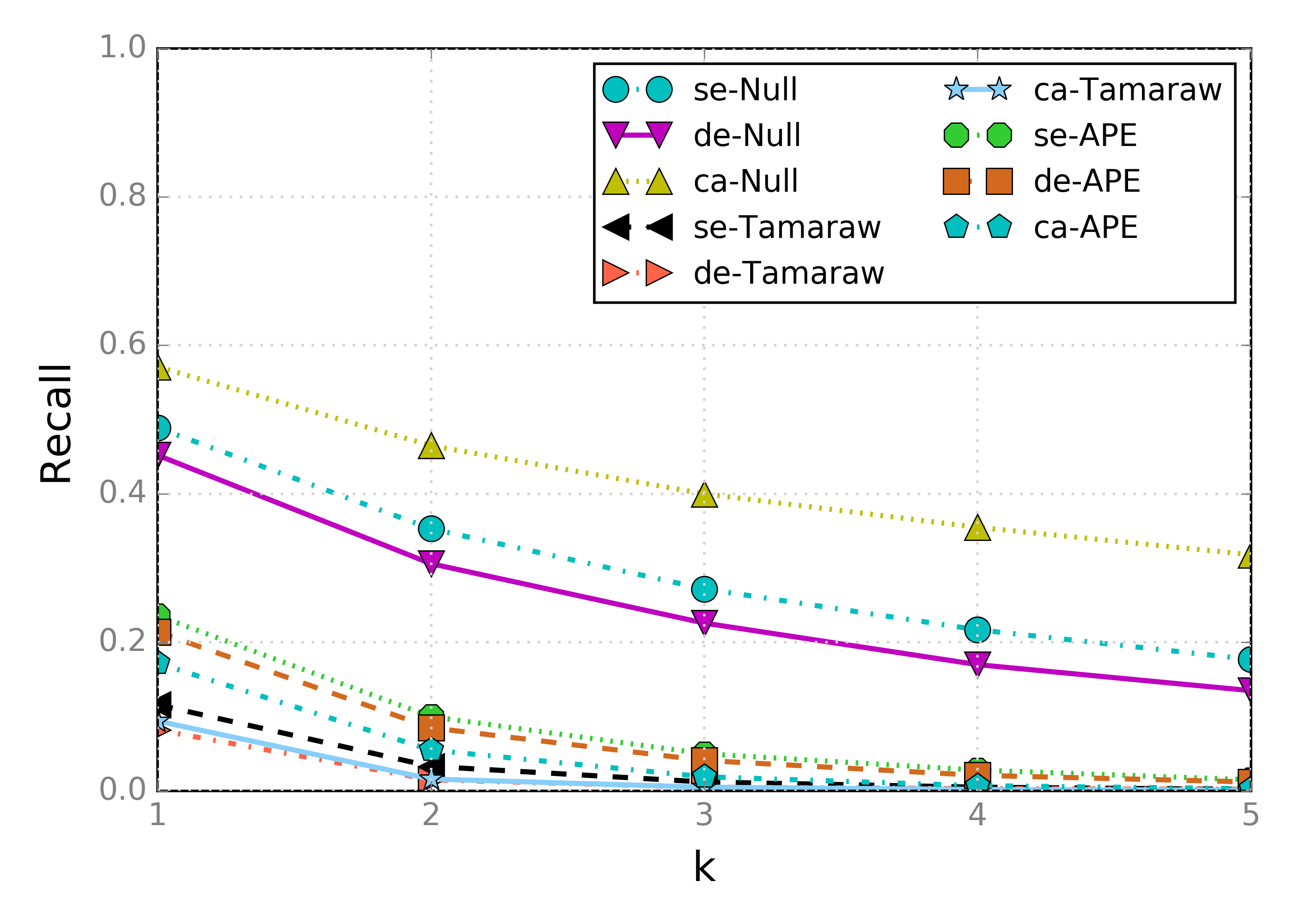
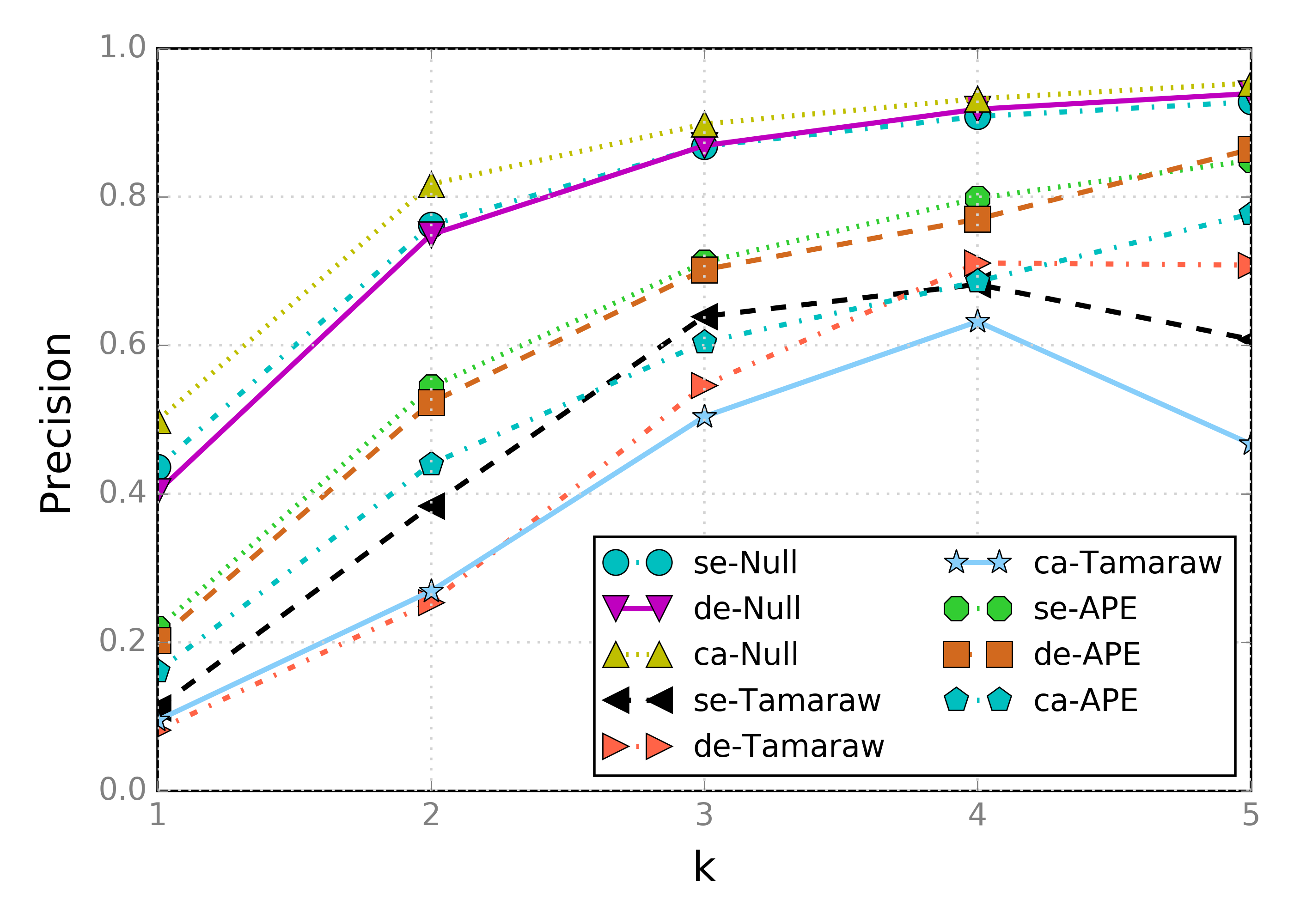
While Tamaraw is consistently a stronger defense, we see that APE’s protection is not far off. Note that APE is using identical parameters for its distribution generation for all three settings. We have also not yet thoroughly explored different parameter choices: we leave this as future work.
The bad
There’s no such thing as a free lunch, and if we use our goodput tool on the
basket2proxy.log files created when running the experiments above we get:
$ goodput basket2proxy.v2kau.log
Null, receive 0.9480±0.0058 0.9478, transmit 0.9739±0.0217 0.9873
APE, receive 0.2827±0.0957 0.2829, transmit 0.4386±0.2133 0.5143
Tamaraw, receive 0.1367±0.0871 0.1181, transmit 0.2086±0.2035 0.1786
$ goodput basket2proxy.v2de.log
Null, receive 0.9499±0.0067 0.9488, transmit 0.9740±0.0229 0.9883
APE, receive 0.2616±0.0824 0.2619, transmit 0.4248±0.2112 0.5173
Tamaraw, receive 0.1347±0.0839 0.1168, transmit 0.2328±0.2281 0.1943
$ goodput basket2proxy.v2ca.log
Null, receive 0.9490±0.0063 0.9485, transmit 0.9732±0.0232 0.9871
APE, receive 0.2503±0.0783 0.2491, transmit 0.4168±0.2048 0.5027
Tamaraw, receive 0.1347±0.0861 0.1121, transmit 0.2022±0.2040 0.1608Comparing Null with APE, we see that Null has about twice the goodput of APE (median, mean slightly higher), while APE has about twice the goodput of Tamaraw (mean, median significantly higher). Please also note that Tamaraw has built-in delay not captured above while APE sends real data nearly as soon as possible (no account taken for buffering of padding data or queueing). For what it’s worth, for WTF-PAD, the authors reported never seing a bandwidth overhead over 60%: a 60% overhead translates to little over 60% goodput, which is significantly better than APE at median 50% goodput.
The ugly
I spent very little time on the actual starting values for the log-normal
distributions, and basically hit a good enough goodput by trial-and-error
then started gathering the datasets shown above. However, no experiment run
suggested that the distributions were sensitive in terms of creating overhead
but not significantly reducing recall. To add to the ugly, when cleaning up some
of the code for APE after running the experiments above I noticed that I had
refactored away one stage transition in the AP state machine (sampling Hb when going from gap to burst mode). Ooops.
Commit 2474924 was the code when running the experiments, and eafbfb8 the fix for the bug (and minor cleanup). I did another quick experiment, this time only with a local bridge and no Tamaraw, we get the following goodput:
$ goodput basket2proxy.v3.log
APE, receive 0.2536±0.0842 0.2514, transmit 0.3304±0.2048 0.3737
Null, receive 0.9479±0.0057 0.9474, transmit 0.9729±0.0219 0.9866As we can see, fixing the state transition bug significantly decreased APE’s goodput for the same parameters. Bummer. Looking at recall and precision:
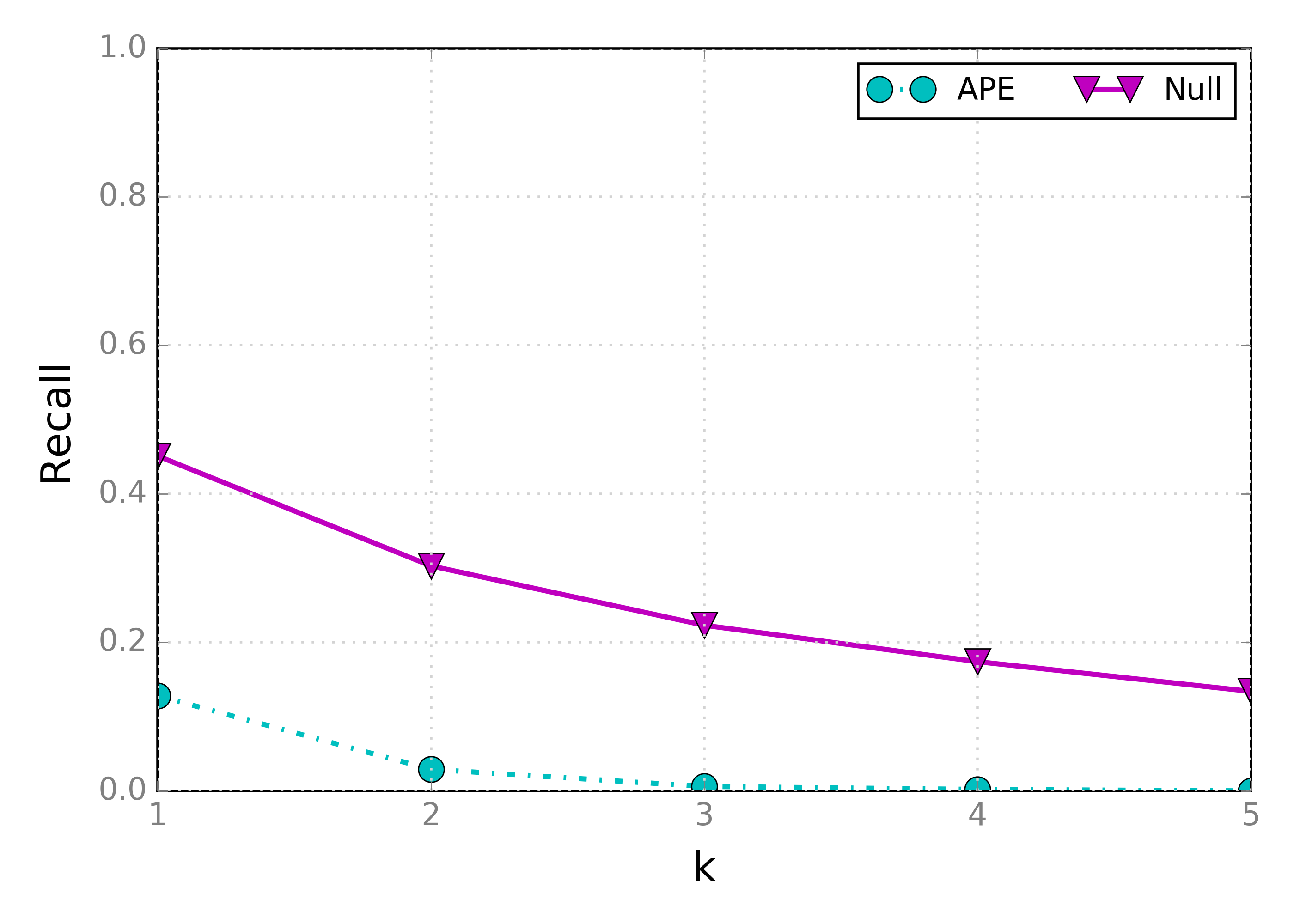
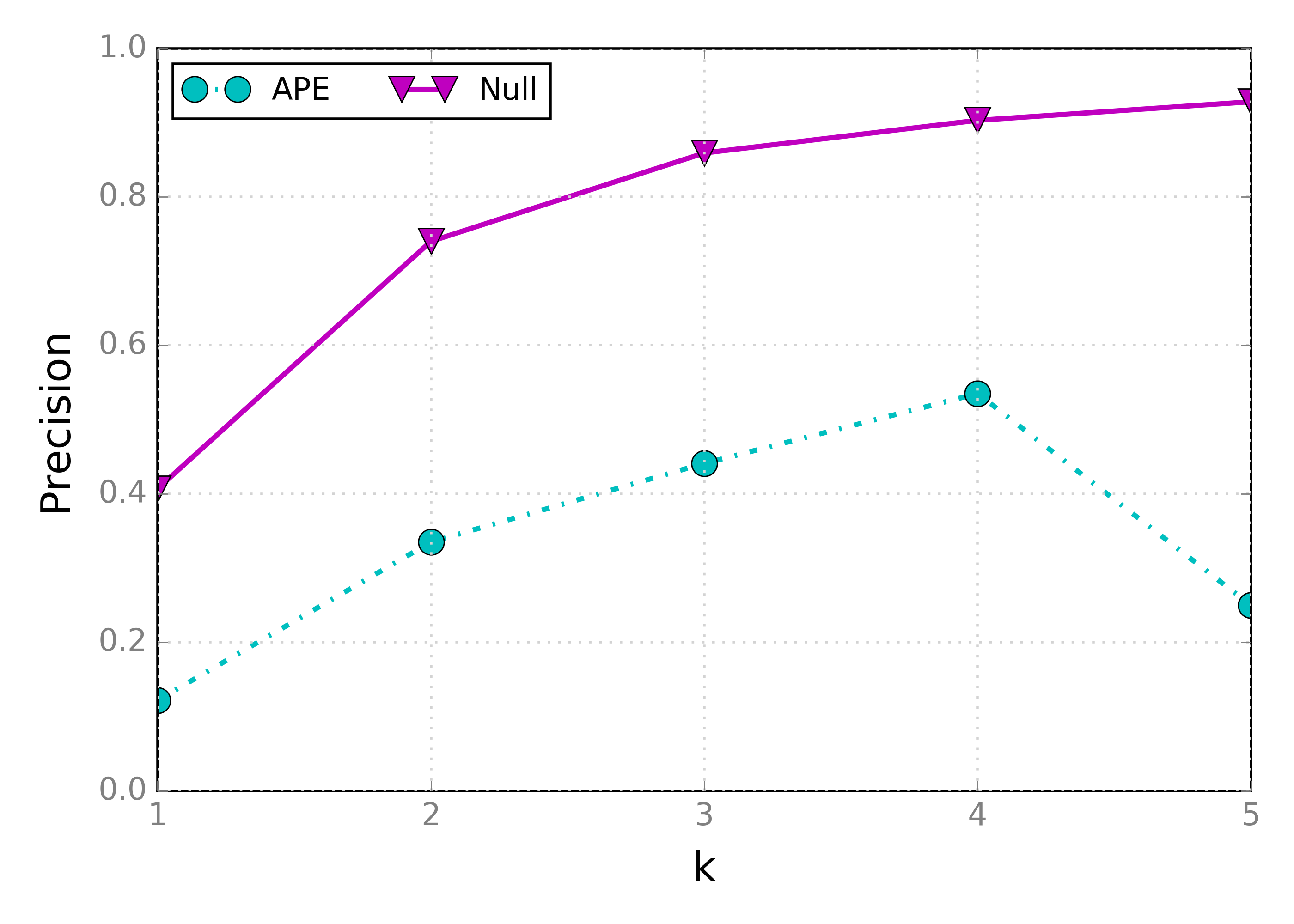
Here we see, on the other hand, that the extra overhead wasn’t wasted: the recall is really close Tamaraw’s observed above.
Conclusions
While some clever statistics—in theory—could be used to distinguish some of the fake data and real data in APE, I remain sceptical of the real-world impact of this seeing as how in practise it is hard to clean out SENDME cells and deal with multi-tab browsning as-is. For the ongoing work on APE, there’s a clear direction forward: further tweak the distributions and evaluate using more feature rich attacks like k-fingerprinting. I’ll spend some limited time on this starting 2017, but the duration of the HOT project is now unfortunately coming to an end.
For WTF-PAD, I’d argue that the results here indicate that simulation-based evaluations of the defense might introduce a lot of complexities around IAT that any pluggable transport defense will actually get “for free”: network conditions, the network stack, queueing algorithm, etc all play a role in influencing the observed IAT. One way to look at it is that an attacker has to distinguish between:
- on the PT client side, data generated by Tor Browser and that of the defense.
- on the PT server side, data generated by the final destination of traffic—subject to the full variability of the Tor network—and that of the defense.
While client-side might be more stable, imagine the variability of all active circuits (with SENDMEs) on the PT server side. This is complex, and to reliably distinguish padding traffic based on IAT a daunting task. I hope this open book of ongoing research will benefit the ongoing work of finding a suitable WF defense for Tor.