In 2014 Wang et al. published the kNN classifier, which is a WF-attack in the form of a supervised machine learning algorithm [0]. The authors kindly provide both the data they used to evaluate the kNN classifier as well as an implementation of the attack for their paper. One key aspect of kNN, as well as most other effective classifiers, is that it extracts features from traffic traces to use in the machine learning algorithm. In Wang’s PhD thesis, he presents the following 4,226 features that is extracted in kNN [1].
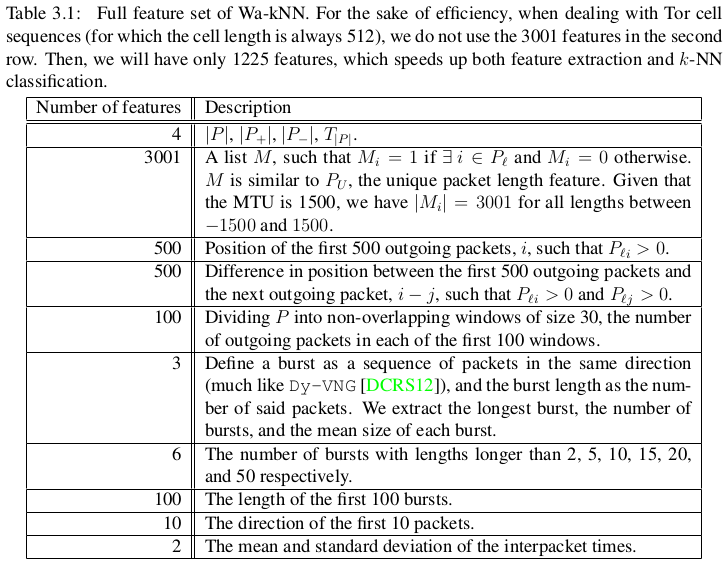
To better understand both the feature extraction as well as kNN itself, we ported the implementation provided by Wang et al. to Go. You can find the repository with the code here. In the process of porting, we found several bugs in the feature extraction and one bug in the machine learning algorithm. The TL;DR is that initial tests show no meaningful differences due to these bugs, but for sake of documentation, the rest of this post details the bugs we found.
Feature extraction
The kNN attack operates on feature files, usually with the suffix “f”. The feature files are generated from traces using fextractor.py to extract features. There are two extractors with the same name, one for the kNN attack and one in the attacks zip-file. The features extracted are explained in Wang’s PhD thesis on page 33 [1].
Note the following:
- There are 3,736 features extracted by both versions of
fextractor.py. The table in the PhD thesis has 4,226 features (490 “missing”). For Tor, 1,225 features are claimed to be useful in the PhD thesis. - For the 2014 Cell traces, 3001 features are the same (as expected), so we have 735 useful features.
- For the different versions of
fextractor.py, the 4th feature is different. The attacks zip-file version ignores time, probably as an artifact of being used for Walkie-Talkie. The data for Walkie-Talkie is even in a format that removes the timing information from the attack. - For “transpositions” features, both versions of
fextractor.pyonly extracts 300x2 features. The PhD thesis lists 500x2 for these features. This accounts for 400 of the missing features compared to the PhD thesis. - For the following 100 features related to “packet distributions”, there is a bug in both versions of the
fextractor.pyscript due to not resetting count to 0. This makes the first extracted feature less useful (maybe not completely useless). - Next are calculations for bursts, later turned into features. There are at least three bugs here in both versions of
fextractor.py:- The burst calculation is only for incoming bursts (inconsistent with the KNN paper, that mentions bursts as outgoing packets only). The cited paper they take this from (Peek-a-Boo…) defines bursts in both directions.
- The
curburstvariable, that tracks the length of the current burst, is never reset. This means that for more than one (incoming) burst, the calculated burst length is ever increasing(ly wrong). - The burst calculation itself adds a burst for each outgoing packet, where the size of the
burst is from
curburst.
- With bursts calculated, the next three features cover the longest burst, the mean size of each burst, and the number of bursts. If there are zero bursts (empty trace), then we divide by zero, but these traces should be discarded regardless.
- Next,
fextractor.pyextracts three burst-related features. The PhD thesis lists six. This accounts for three more missing features. - More burst-related features follows, with
fextractor.pyextracting the length of the first five bursts. The PhD thesis claims 100. This accounts for another 95 missing features. - Finally,
fextractor.pyextracts the direction of the first 20 packets. The thesis claims 10. This increases the feature count by 10 undocumented features. The kNN paper sets this to 20 though. - While
fextractor.pyis now done, the PhD thesis specifies two more features: the mean and standard deviation of the interpacket times.
Machine learning algorithm
The training algorithm has a bug in the training algorithm for finding maxgood. In the code below, the check should be if feat[recogoodlist[k]][f] == -1, not if feat[recobadlist[k]][f] == -1. This is because in the abs() call, a feature with -1 is the same as no such feature.
for (int k = 0; k < RECOPOINTS_NUM; k++) {
float n = abs(feat[i][f] - feat[recogoodlist[k]][f]);
if (feat[i][f] == -1 or feat[recobadlist[k]][f] == -1)
n = 0;
if (n >= maxgood) maxgood = n;
}Does this matter?
Using the 100x90 + 9000 dataset from Wang et al., comparing the ported original kNN (that produces identical output) and the fixes version (k=2):
$ go run src/attacks/knn.orig/knn.orig.go
2016/02/26 13:06:00 loaded instances: main
2016/02/26 13:06:01 loaded instances: training
2016/02/26 13:06:02 loaded instances: testing
2016/02/26 13:06:04 loaded instances: open
2016/02/26 13:06:04 starting to learn distance...
distance... 8999 (0-9000)
2016/02/26 13:23:36 finished
2016/02/26 13:23:36 started computing accuracy...
accuracy... 17999 (0-18000)
2016/02/26 14:26:36 finished
2016/02/26 14:26:36 Accuracy: 0.870667 0.989889
$ go run src/attacks/knn.fixed/knn.fixed.go
2016/02/26 13:06:03 loaded instances: main
2016/02/26 13:06:03 loaded instances: training
2016/02/26 13:06:04 loaded instances: testing
2016/02/26 13:06:06 loaded instances: open
2016/02/26 13:06:06 starting to learn distance...
distance... 8999 (0-9000)
2016/02/26 13:11:43 finished
2016/02/26 13:11:43 started computing accuracy...
accuracy... 17999 (0-18000)
2016/02/26 13:31:16 finished
2016/02/26 13:31:16 Accuracy: 0.872556 0.989889So three times as fast (only due to feature removal) and ~0.2% better TPR. This might just as well be noise, so no, it does not appear to matter at all.
Sources
- [0] T. Wang, X. Cai, R. Nithyanand, R. Johnson and I. Goldberg. Effective Attacks and Provable Defenses for Website Fingerprinting. USENIX 2014.
- [1] Section 3.1.13 in Tao Wang’s PhD thesis.